it provides an abstraction of data, so that your application can work with a simple abstraction that has an interface like in memory collection. Adding, removing, updating, and selecting items from this collection is done through a series of straightforward methods, without the need to deal with database concerns like connections, commands, cursors, or readers.
Using this pattern can help achieve loose coupling and can keep domain objects persistence ignorant.
Simple Active Record (No Repository ) == RDG++
Simple Data Mapper (No Repository) == TDG++
Respository Based Active Record = Simple Active Record++
Repository Based Data Mapper = Simple Data Mapper++
Respository (Active Record) = Simple Active Record++
Repository (Data Mapper) = Simple Data Mapper++
mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects.
Repository is a Data Mapper with additional advantage of In-memory database in between
Repository = Data Mapper + In-Memory Version of Database Repository
Repository Pattern extends Data Mapper Pattern add Repository Benefits
Repository Pattern further Abstract the DataMappers and make the DB Free
In context of Onion Arch, Repository pushed the DB concerns out of the Data Project. Now our all Application Layer, Domain Layer and Data Layer all are DB Free.
In Data Mapper Pattern, our DataMapper is dealing with Persistence Concerns/DB Concerns.
Non-Repository Data Mapper know the SQL, Persistence or DB Concerns, Transactions
Domain Model is OO
But Data Mapper is SQL/DB/Persistence/Transaction Known.
Data Mapper ==> DB
Data is mapped to DB in mapper, therefore mapper know about DB
=============================================
Repository Transform the Database and Present it like the In-Memory Collection of objects
Repository give and Virtual In-Memory Database consistent fo Collections.
Repository Data Mapper is un know the SQL, Persistence or DB Concerns, Transactions
Domain Model is OO
Data Mapper is also OO now.
Data Mapper is like dealing with Collection of Objects.
It does not seem we are dealing with some DB
Data Mapper ==> In Memory Repository ==> DB
Data is mapped to In Memory Version of DB, therefore therefore mapper unknow to DB
Other Concepts those are important with Repository are following
Query Objects and Metadata Mapping, UOW
With the addtion of OO In-Memeory Verions of DB we need two more things to make the
translations between OO and DB
OO represnetation of the Query
Object Relations Mapping Tables. Which Class is mapped to which Table and Which Column goes to which filed
Transactions and Concurrency issues in Data Access

Using this pattern can help achieve loose coupling and can keep domain objects persistence ignorant.
Simple Active Record (No Repository ) == RDG++
Simple Data Mapper (No Repository) == TDG++
Respository Based Active Record = Simple Active Record++
Repository Based Data Mapper = Simple Data Mapper++
Respository (Active Record) = Simple Active Record++
Repository (Data Mapper) = Simple Data Mapper++
mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects.
Repository is a Data Mapper with additional advantage of In-memory database in between
Repository = Data Mapper + In-Memory Version of Database Repository
Repository Pattern extends Data Mapper Pattern add Repository Benefits
Repository Pattern further Abstract the DataMappers and make the DB Free
In context of Onion Arch, Repository pushed the DB concerns out of the Data Project. Now our all Application Layer, Domain Layer and Data Layer all are DB Free.
In Data Mapper Pattern, our DataMapper is dealing with Persistence Concerns/DB Concerns.
Non-Repository Data Mapper know the SQL, Persistence or DB Concerns, Transactions
Domain Model is OO
But Data Mapper is SQL/DB/Persistence/Transaction Known.
Data Mapper ==> DB
Data is mapped to DB in mapper, therefore mapper know about DB
=============================================
Repository Transform the Database and Present it like the In-Memory Collection of objects
Repository give and Virtual In-Memory Database consistent fo Collections.
Repository Data Mapper is un know the SQL, Persistence or DB Concerns, Transactions
Domain Model is OO
Data Mapper is also OO now.
Data Mapper is like dealing with Collection of Objects.
It does not seem we are dealing with some DB
Data Mapper ==> In Memory Repository ==> DB
Data is mapped to In Memory Version of DB, therefore therefore mapper unknow to DB
A system with a complex domain model often benefits from a layer, such as the one provided by Data Mapper (165), that isolates domain objects from details of the database access code.
In such systems it can be worthwhile to build another layer of abstraction over the mapping layer where query construction code is concentrated.
This becomes more important when there are a large number of domain classes or heavy querying.
In these cases particularly, adding this layer helps minimize duplicate query logic.??????
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection.
Client objects construct query specifications declaratively and submit them to Repository for satisfaction.
Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes.
Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer.
Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers.
============================================================Other Concepts those are important with Repository are following
Query Objects and Metadata Mapping, UOW
With the addtion of OO In-Memeory Verions of DB we need two more things to make the
translations between OO and DB
OO represnetation of the Query
Object Relations Mapping Tables. Which Class is mapped to which Table and Which Column goes to which filed
Transactions and Concurrency issues in Data Access
Metadata Mapping
Holds details of object-relational mapping in metadata.
For a full description see P of EAA page 306
Much of the code that deals with object-relational mapping describes how fields in the database correspond to fields in in-memory objects. The resulting code tends to be tedious and repetitive to write. A Metadata Mapping allows developers to define the mappings in a simple tabular form, which can then be processed by generic code to carry out the details of reading, inserting, and updating the data.
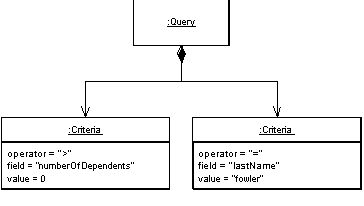
Query Object
An object that represents a database query.
For a full description see P of EAA page 316
SQL can be an involved language, and many developers aren't particularly familiar with it. Furthermore, you need to know what the database schema looks like to form queries. You can avoid this by creating specialized finder methods that hide the SQL inside parameterized methods, but that makes it dif-ficult to form more ad hoc queries. It also leads to duplication in the SQL state-ments should the database schema change.
A Query Object is an interpreter [Gang of Four], that is, a structure of objects that can form itself into a SQL query. You can create this query by refer-ring to classes and fields rather than tables and columns. In this way those who write the queries can do so independently of the database schema and changes to the schema can be localized in a single place.

Unit of Work
Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.
For a full description see P of EAA page 184
When you're pulling data in and out of a database, it's important to keep track of what you've changed; otherwise, that data won't be written back into the database. Similarly you have to insert new objects you create and remove any objects you delete.
You can change the database with each change to your object model, but this can lead to lots of very small database calls, which ends up being very slow. Furthermore it requires you to have a transaction open for the whole interaction, which is impractical if you have a business transaction that spans multiple requests. The situation is even worse if you need to keep track of the objects you've read so you can avoid inconsistent reads.
A Unit of Work keeps track of everything you do during a business transaction that can affect the database. When you're done, it figures out everything that needs to be done to alter the database as a result of your work.
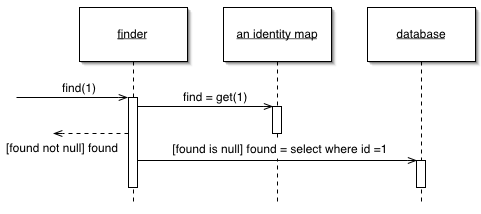
Identity Map
Ensures that each object gets loaded only once by keeping every loaded object in a map. Looks up objects using the map when referring to them.
For a full description see P of EAA page 195
An old proverb says that a man with two watches never knows what time it is. If two watches are confusing, you can get in an even bigger mess with loading objects from a database. If you aren't careful you can load the data from the same database record into two different objects. Then, when you update them both you'll have an interesting time writing the changes out to the database correctly.
Related to this is an obvious performance problem. If you load the same data more than once you're incurring an expensive cost in remote calls. Thus, not loading the same data twice doesn't just help correctness, but can also speed up your application.
An Identity Map keeps a record of all objects that have been read from the database in a single business transaction. Whenever you want an object, you check the Identity Map first to see if you already have it.
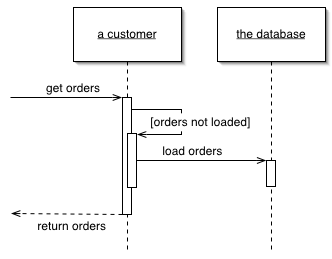
Lazy Load
An object that doesn't contain all of the data you need but knows how to get it.
For a full description see P of EAA page 200
For loading data from a database into memory it's handy to design things so that as you load an object of interest you also load the objects that are related to it. This makes loading easier on the developer using the object, who otherwise has to load all the objects he needs explicitly.
However, if you take this to its logical conclusion, you reach the point where loading one object can have the effect of loading a huge number of related objects - something that hurts performance when only a few of the objects are actually needed.
A Lazy Load interrupts this loading process for the moment, leaving a marker in the object structure so that if the data is needed it can be loaded only when it is used. As many people know, if you're lazy about doing things you'll win when it turns out you don't need to do them at all.
There are four main varieties of lazy load. Lazy Initialization uses a special marker value (usually null) to indicate a field isn't loaded. Every access to the field checks the field for the marker value and if unloaded, loads it. Virtual Proxy is an object with the same interface as the real object. The first time one of its methods are called it loads the real object and then delegates. Value Holder is an object with a getValue method. Clients call getValue to get the real object, the first call triggers the load. A ghost is the real object without any data. The first time you call a method the ghost loads the full data into its fields.
These approaches vary somewhat subtly and have various trade-offs. You can also use combination approaches. The book contains the full discussion and examples.
4 Common Mistakes with the Repository Pattern
One repository per domain - Anti Pattern
You should think of a repository as a collection of domain objects in memory. If you’re building an application called Vega, you shouldn’t have a repository like the following:
1
2
3
| public class VegaRepository {} |
Instead, you should have a separate repository per domain class, like OrderRepository, ShippingRepository and ProductRepository.
Repositories that return view models/DTOs- Anti Pattern
Once again, a repository is like a collection of domain objects. So it should not return view models/DTOs or anything that is not a domain object. I’ve seen many students using AutoMapper inside their repository methods:
1
2
3
4
5
6
| public IEnumerable<OrderViewModel> GetOrders() { var orders = context.Orders.ToList(); return mapper.Map<List<Order>, List<OrderViewModel>(orders);} |
Mapping is not the responsibility of the repository. It’s the responsibility of your controllers. Your repositories should return domain objects and the client of the repository can decide if it needs to do the mapping. By mapping the domain objects to view models (or something else) inside a repository, you prevent the client of your repositories from getting access to the underlying domain object. What if you return OrderViewModel but somewhere else you need OrderDetailsViewModel or OrderSnapshotViewModel? So, the client of the repository should decide what it wants to map the Order object to.
Save/Update method in repositories - Anti Pattern
Yet another very common mistake! As I’ve explained in my YouTube video before, your repositories should not have a Save() or Update() method. I repeat: think of a repository as a collection of domain objects in memory. Do collections have a Save() or Update() method? No! Here’s an example:
1
2
3
4
5
6
7
| var list = new List<int>();list.Add(1);list.Remove(1);list.Find(1);list.Save(); // doesn't exist!list.Update(); // doesn't exist! |
Another reason your repositories should not have a Save() method is because sometimes as part of a transaction you may work with multiple repositories. And then you want to persist the changes across multiple repositories in one transaction. Here’s an example:
1
2
3
4
5
| orderRepository.Add(order);orderRepository.Save();shippingRepository.Add(shipping);shippingRepository.Save(); |
Can you see the problem in this code? For each change, we need a separate call to the Save() method on the corresponding repository. What if one of these calls to the Save() method fails? You’ll end up with a database in an inconsistent state. Yes, we can wrap that whole thing inside a transaction to make it even more ugly!
A pattern that goes hand in hand with the repository pattern is the unit of work. With the unit of work, we can re-write that ugly code like this:
1
2
3
| orderRepository.Add(order);shippingRepository.Add(shipping);unitOfWork.Complete(); |
Now, either both objects are saved together or none are saved. The database will always be in a consistent state. No need to wrap this block inside a transaction. No need for two separate calls to the Save() method!
If you want to learn how to implement the repository and unit of work pattern together, watch my YouTube video here.
Repositories that return IQueryable- Anti Pattern
One of the reasons we use the repository pattern is to encapsulate fat queries. These queries make it hard to read, understand and test actions in ASP.NET MVC controllers. Also, as your application grows, the chances of you repeating a fat query in multiple places increases. With the repository pattern, we encapsulate these queries inside repository classes. The result is slimmer, cleaner, more maintainable and easier-to-test actions. Consider this example:
1
2
3
4
| var orders = context.Orders .Include(o => o.Details) .ThenInclude(d => d.Product) .Where(o => o.CustomerId == 1234); |
Here we are directly using a DbContext without the repository pattern. When your repository methods return IQueryable, someone else is going to get that IQueryable and compose a query on top of it. Here’s the result:
1
2
3
4
| var orders = repository.GetOrders() .Include(o => o.Details) .ThenInclude(d => d.Product) .Where(o => o.CustomerId == 1234); |
Can you see the difference between these two code snippets? The only difference is in the first line. In the first example, we use context.Orders, in the second we use repository.GetOrders().So, what problem is this repository solving? Nothing!
Your repositories should return domain objects. So, the GetOrders() method should return an IEnumerable. With this, the second example can be re-written as:
1
| var orders = repository.GetOrders(1234); |
See the difference?
What are the other issues you’ve seen in the implementation of the repository pattern? Share your thoughts!
If you enjoyed this article, please share it.
No comments:
Post a Comment